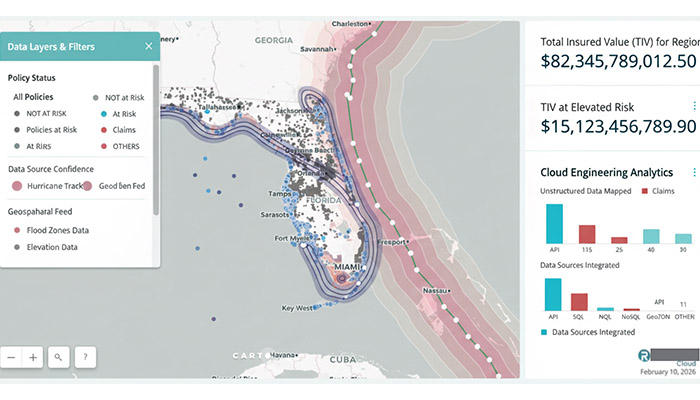
LH-PVI is a data intelligence platform for a private insurance company that transforms unstructured policy documents, claims files, and inspection reports into structured geospatial intelligence — enabling 70% faster processing and surfacing risk patterns that were invisible in the original documents.
The insurance industry sits on decades of unstructured data — handwritten inspection notes, scanned PDFs, inconsistent address formats, free-text claim descriptions — that contains enormous analytical value locked behind format chaos. LH-PVI was built to unlock that value without requiring the insurer to change their existing workflows.
The insurer had accumulated a substantial historical dataset — policy documents, claims files, inspection reports, loss run summaries — across decades of operations. The problem was not a lack of data. The problem was that the data existed in formats that made it analytically useless: scanned PDFs with handwritten annotations, carbon copies of inspection reports, addresses formatted differently across every regional office, and free-text claim descriptions that required reading comprehension to interpret.
Manual processing was the only option, and manual processing was expensive, slow, and inconsistent. Complex claims required an analyst to cross-reference multiple documents against property records, maps, and regulatory requirements before a coverage decision could be made. There was also no spatial awareness in the portfolio at all — policies and claims existed as text records with no geospatial context, which meant risk clustering, flood zone exposure, and proximity-based underwriting factors simply weren't calculable.
The core architectural principle was to design the pipeline around the insurer's actual document chaos — not around clean, well-formatted inputs that don't exist in production. Production ML means processing what exists. A system that requires clean inputs will never process the legacy archive. A system that handles the full range of real document messiness will.
The approach had three sequential layers: extract the meaning from the document (regardless of format), resolve the location (regardless of how the address was written), and enrich with geospatial context (flood zone, zoning, proximity factors) automatically. The insurer's analysts receive structured output that maps directly into their existing systems. No workflow change required.
The pipeline is GCP-native throughout, with each stage designed to be independently scalable and observable. The critical design constraint was that no decrypted document ever touches persistent storage outside Cloud Storage — processing happens ephemerally in Cloud Functions, and only the structured output is retained long-term.
See the full portfolio — production AI systems across asset management, property intelligence, and voice biometrics.